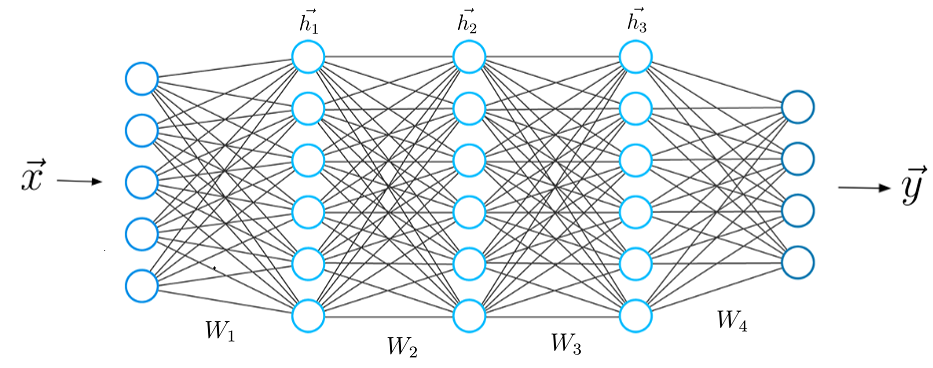
Introduction
Hello to another blog art, where we try to learn together something interesting. Few asked me to give a review on deep learning from scratch. And I thought, why I don’t create my list of articles too. And here we are in the attempt to create a deep learning model from scrach. I am sure it will be a tough journey, but we will get it done together and will learn something new in the process.
What is deep learning?
That’s a repetitve question that many new to the field asks about. Let’s wrap it here once and for all. Simply put, deep learning is a subset of methods for machine learning. Where, which is a field dedicated to the study and development of machines that can learn (sometimes with the goal of eventually attaining general artificial intelligence).
The above defination can be thought of as the acdemic defination. But in industry, deep learning is used to solve practical tasks in a variety of fields such as:
- Computer vision (image).
- Natural language processing (text).
- Automatic speech recognition (audio).
In short, deep learning is a subset of methods in the machine learning toolbox, primarily using artificial neural networks, which are a class of algorithm loosely inspired by the human brain.
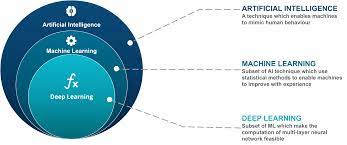
Please Note that in this figure isn’t generalizable, as not all of deep learning is focused around pursuing generalized artificial intelligence (sentient machines as in the movies). Many applications of this technology are used to solve a wide variety of problems in industry.
What is machine learning?
Now you know that deep learning is a subset of machine learning. So, you should ask what is machine learning? Most generally, it is what its name implies. Machine learning is a subfield of computer science wherein machines learn to perform tasks for which they were not explicitly programmed.
I mention direct and indirect imitation as a parallel to the two main types of machine learning: supervised and unsupervised. Supervised machine learning is the direct imitation of a pattern between two datasets. It’s always attempting to take an input dataset and transform it into an output dataset. This can be an incredibly powerful and useful capability. Consider the following examples (input datasets in bold and output datasets in other bold):
- Using the pixels of an image to detect the presence or absence of a cat.
- Using someone’s quotes/words to predict whether they’re happy or sad or angry.
- Using weather sensor data to predict the probability of rain.
- Using a raw audio file to predict a transcript of the audio.
These are all supervised machine learning tasks. In all cases, the machine learning algorithm is attempting to imitate the pattern between the two datasets in such a way that it can use one dataset to predict the other. For any of these examples, imagine if you had the power to predict the output dataset given only the input dataset.
Categorize Machine Learning
After we got to understand what machine learning and deep learning is, now we need to see the different types of machine learning and deep learning. In which we can understand the tasks that out model is trying to acheive.
Supervised Machine Learning
One of the most popular types of machine learning is Supervised Learning. It is a method for changing or transforming one dataset into another. Becasue the input will a set of data and the output is another different set of data.
One particularly popular topic in text classification is to predict the sentiment of a piece of text, like a tweet or a product review. This is widely used in the e-commerce industry to help companies to determine negative comments made by customers.
So, the inpput is customer review of the product as a text and the output is his sentiment (positive or negative). Or, given an image of an animal, we can predict what is the animal inside (cat or dog).
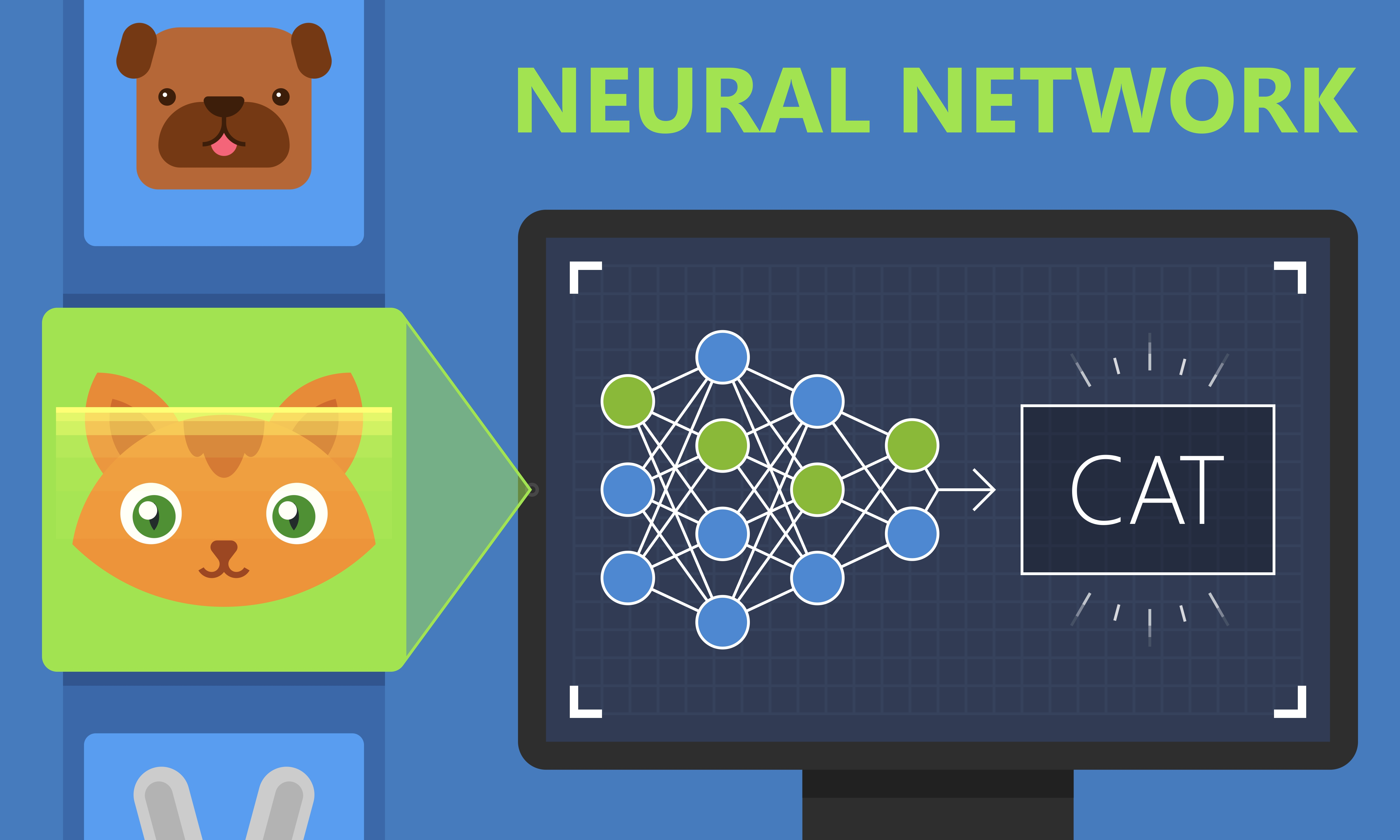
Supervised machine learning is useful for taking what you know as input and quickly transforming it into what you want to know. This allows supervised machine learning algorithms to extend human intelligence and capabilities in a seemingly endless number of ways.
Actually, for the of the articles list, we will deal with many examples that uses the supervised machine learning. And we’ll be creating algorithms that can take input data that is and transform it into valuable output data.
Unsupervised Machine Learning
Unsupervised learning shares a property in common with supervised learning: it transforms one dataset into another. But of course there’s difference, which is that the dataset that it transforms into is not previously known or understood. Unlike supervised learning, there is no “right answer” that you’re trying to get the model to duplicate. You just tell an unsupervised algorithm to “find patterns in this data and tell me about them.”
For example, clustering a dataset into groups is a type of unsupervised learning. Clustering transforms a sequence of datapoints into a sequence of cluster labels. If it learns 10 clusters, it’s common for these labels to be the numbers 1–10. Each datapoint will be assigned to a number based on which cluster it’s in.
Clustering is an unsupervised technique where the goal is to find natural groups or clusters in a feature space and interpret the input data. There are many different clustering algorithms. One common approach is to divide the data points in a way that each data point falls into a group that is similar to other data points in the same group based on a predefined similarity or distance metric in the feature space.
Thus, the dataset turns from a bunch of datapoints into a bunch of labels. Why are the labels numbers? The algorithm doesn’t tell you what the clusters are. How could it know? It just says, “Hey scientist! I found some structure. It looks like there are groups in your data. Here they are!”

Another Categorization Happens
After we categorized any model into Supservised & Unsupervised, we can also put another type of categorizations. Let’s not waster more time and see it.
Parametric vs. nonparametric learning
Now, we’re going to discuss another way to divide the same machine learning algorithms into two groups:
- parametric.
- nonparametric.
If we combined the two categories, we will find that there are four different types of algorithms to choose from. An algorithm is either unsupervised or supervised, and either parametric or nonparametric.
Whereas the previous section on supervision is about the type of pattern being learned, parametricism is about the way the learning is stored and often, by extension, the method for learning.
First, let’s look at the formal definitions of parametricism versus nonparametricism. For the record, there’s still some debate around the exact difference.
- A parametric model is characterized by having a fixed number of parameters.
- A nonparametric model’s number of parameters is infinite (determined by data).
As an example, let’s say the problem is to fit a square peg into the correct (square) hole. Some humans (such as babies) just jam it into all the holes until it fits somewhere (parametric). A teenager, however, may count the number of sides (four) and then search for the hole with an equal number (nonparametric). Parametric models tend to use trial and error, whereas nonparametric models tend to count. Let’s look closer.
Supervised parametric learning
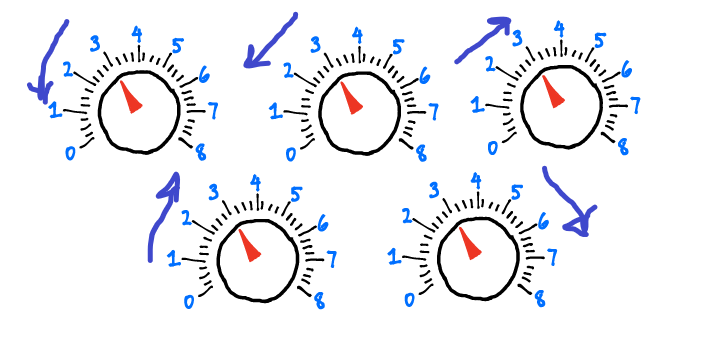
Oversimplified: Trial-and-error learning using knobs Supervised parametric learning machines are machines with a fixed number of knobs (that’s the parametric part), wherein learning occurs by turning the knobs. Input data comes in, is processed based on the angle of the knobs, and is transformed into a prediction.
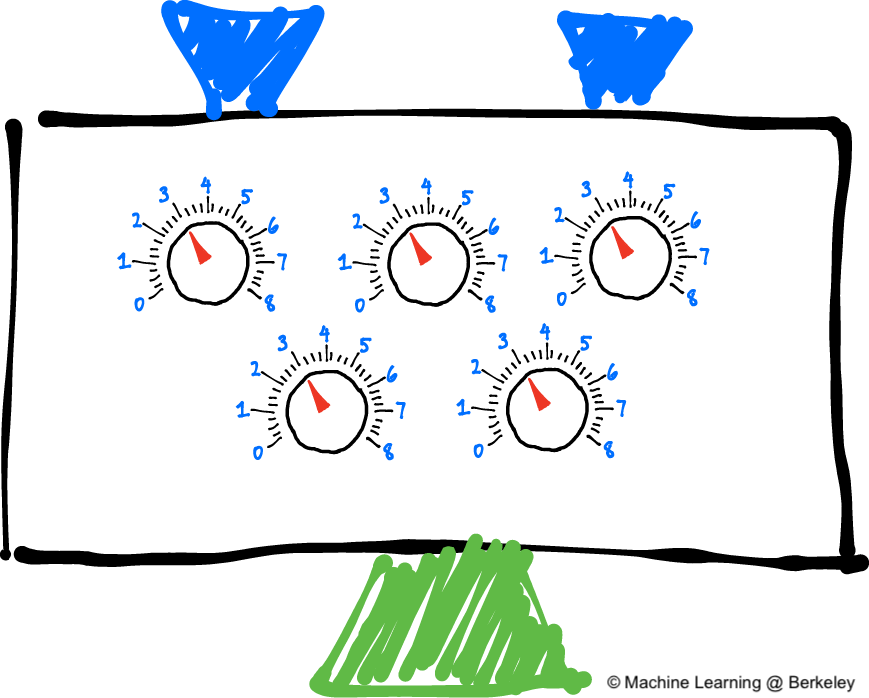
Learning is accomplished by turning the knobs to different angles. If you’re trying to predict the probability that the Red Sox will win the World Series, then this model would first take data (such as sports stats like win/loss record or average number of toes per player) and make a prediction (such as 98% chance). Next, the model would observe whether or not the Red Sox actually won. After it knew whether they won, the learning algorithm would update the knobs to make a more accurate prediction the next time it sees the same or similar input data. Perhaps it would “turn up” the “win/loss record” knob if the team’s win/loss record was a good predictor. Inversely, it might “turn down” the “average number of toes” knob if that datapoint wasn’t a good predictor. This is how parametric models learn! Note that the entirety of what the model has learned can be captured in the positions of the knobs at any given time. You can also think of this type of learning model as a search algorithm. You’re “searching” for the appropriate knob configuration by trying configurations, adjusting them, and retrying. Note further that the notion of trial and error isn’t the formal definition, but it’s a common (with exceptions) property to parametric models. When there is an arbitrary (but fixed) number of knobs to turn, some level of searching is required to find the optimal configuration. This is in contrast to nonparametric learning, which is often count based and (more or less) adds new knobs when it finds something new to count.
Machine Learning Model Breakdown
Let’s break down supervised parametric learning into its three steps.
Step 1: Predict
To illustrate supervised parametric learning, let’s continue with the sports analogy of trying to predict whether the Red Rox will win the World Series. The first step, as mentioned, is to gather sports statistics, send them through the machine, and make a prediction about the probability that the Red Sox will win.
Step 2: Compare to the truth pattern
The second step is to compare the prediction (98%) with the pattern you care about (whether the Red Sox won). Sadly, they lost, so the comparison is Pred: 98% > Truth: 0% This step recognizes that if the model had predicted 0%, it would have perfectly predicted the upcoming loss of the team. You want the machine to be accurate, which leads to step 3.
Step 3: Learn the pattern
This step adjusts the knobs by studying both how much the model missed by (98%) and what the input data was (sports stats) at the time of prediction. This step then turns the knobs to make a more accurate prediction given the input data. In theory, the next time this step saw the same sports stats, the prediction would be lower than 98%. Note that each knob represents the prediction’s sensitivity to different types of input data. That’s what you’re changing when you “learn.”
Summary
Now we came to the end of this article, we’ve gone a level deeper into the various flavors of machine learning. You learned that a machine learning algorithm is either supervised or unsupervised and either parametric or nonparametric. Furthermore, we explored exactly what makes these four different groups of algorithms distinct.
Until now, we’ve stayed at a conceptual level as you got your bearings in the field as a whole and your place in it. In the next aricle, you’ll build your first neural network, and all subsequent articles will be project based. So, stay tuned.