Introduction
Today, Deep Learning become a usual thing when it come to build an intelligent model to learn few stuff about data. Deep Learning which is a part of machine learning in Artificial Intelligence(AI) has networks which can extract information from unstructured data.
In this article, we will have a small discussion about how increase/decrease data will impact your Deep Learning model.
What is Deep Learning? (if you are new 🤓)
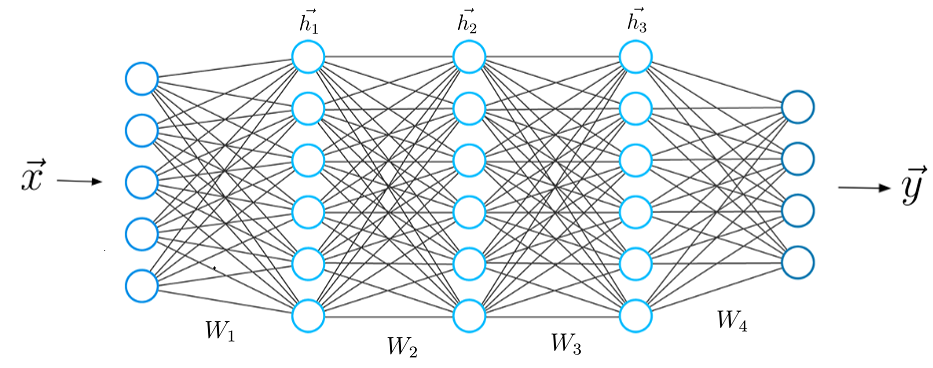
Deep learning models are algorithms which instead of being based on task-specific algorithms are based on learning data representations. This means that these models, through their artificial neural networks, create many different levels of results instead of focusing on just one set of results.
These models are increasingly being used in the fields of computer vision, speech recognition and in the field of medicine or more specifically in the field of new drug development.
Deep Learning and Data
As with anything else, though these deep learning models are only as good as what is put into them and in the case of learning models, databases are put into them. Obviously whoever wants to create the model will know what they want them to create and so will also obviously know which databases need to be used in order for the model to create relevant results, however, the size of the database used can greatly affect the model’s effectiveness.
The challenge in making an effective and useful deep learning model is therefore in knowing the correct size of the database to use. Using a database which is too small will effectively result in the model creating oversimplified results on all levels, meaning it is only effective for the bare minimum of applications. On the other hand, however, using a database which is too large may create too many levels for any of them to have any real practical uses.
Fortunately, the algorithms used in these models have two qualities that can help the person setting them up. The quality is an ability to possess a certain amount of randomness and the second quality is that they can afford slight adjustments. This means that the same database can be fed through the model several times but with slight adjustments being made each time. The adjustments and the randomness of the model will result in different levels being created despite the same database being continuously used.
By running the same database through the same model several times, the results can be looked at to determine the effectiveness of that particular model on that particular sized database. The size of the database can then be changed accordingly and similar tests carried out. With each set of results from the different sized databases being studied, it can be determined what size database would most effectively create the desired number of different levels in the model’s results and therefore render the model as effective as possible for its desired purpose.
Algorithms today are an essential part of practically anything we use today from apps on our phones to social media sites and so understanding them plays a key role in the future of technologies. Not only are algorithms used in new technology but they are also used to create that new technology and there use in deep learning models is only one example of that. Even algorithms need feeding though and in the case of most the feed is made up of varying sizes of databases.
Final Words 👌👌
We will end our discussion here, but in the future I might add few words about some experiments that might be helpful to understand how really data size increase/decrease might impact your model and how it learns.
Also, please check the other articles too. See you soon.